Pick One Already
Scraping for the Best Movies on Netflix
Personal project for movie lovers unsure of the film to stream next, this one-model rails website scrapes popular ratings and displays them simply for fast picking.
Working with Streaming Availability API
For many people, picking the right movie might take more time than actually watching it. To make a website that collected all the best movies in one place, I had to use an API that tracked which movies or tv shows were streaming based on the 1) platform (Netflix, Disney, etc) and 2) country. I chose Movie of the Night’s Streaming Availability API that provided every field I needed to create a comprehensive database. The movies are selected from the following criteria:
- IMDB rating is above 60 (this comes as a JSON value in the API and is not shown on the website because the rating is unreliable in my option).
- Metacritic score is over 35 if found (this number was scraped on IMDB’s website).
- Rotten Tomato url is found and the score is over 45 (scraping this was more difficult, see next heading).
A user can generate a random sample of 5 movies from the database. The movie poster, Rotten Tomatoes rating, and Metacritic rating are displayed and can be clicked on to show more information about the film, such as a short description, cast, and links to the rating websites and a youtube trailer. If the user wants to save the movie to watch later, she can save it to her collection. This movie then appears in her watchlist and can be removed any time.
Limitations: The API limits 100 GET requests per day for the free version. This means that the database grows everyday and is called by changing the 'page' value of the API. One 'page' of results is only 8 movies, and so a while loop is necessary to go through each page and check if the scraped ratings match the criteria. In addition, Streaming Availability 'pages' change with movies getting deleted/added to the steaming service, and due to the limited capaiblities of accessing only 100 requests a day, my database is not always up-to-date with the latest changes. These problems can be resolved by buying the PRO version of the API.
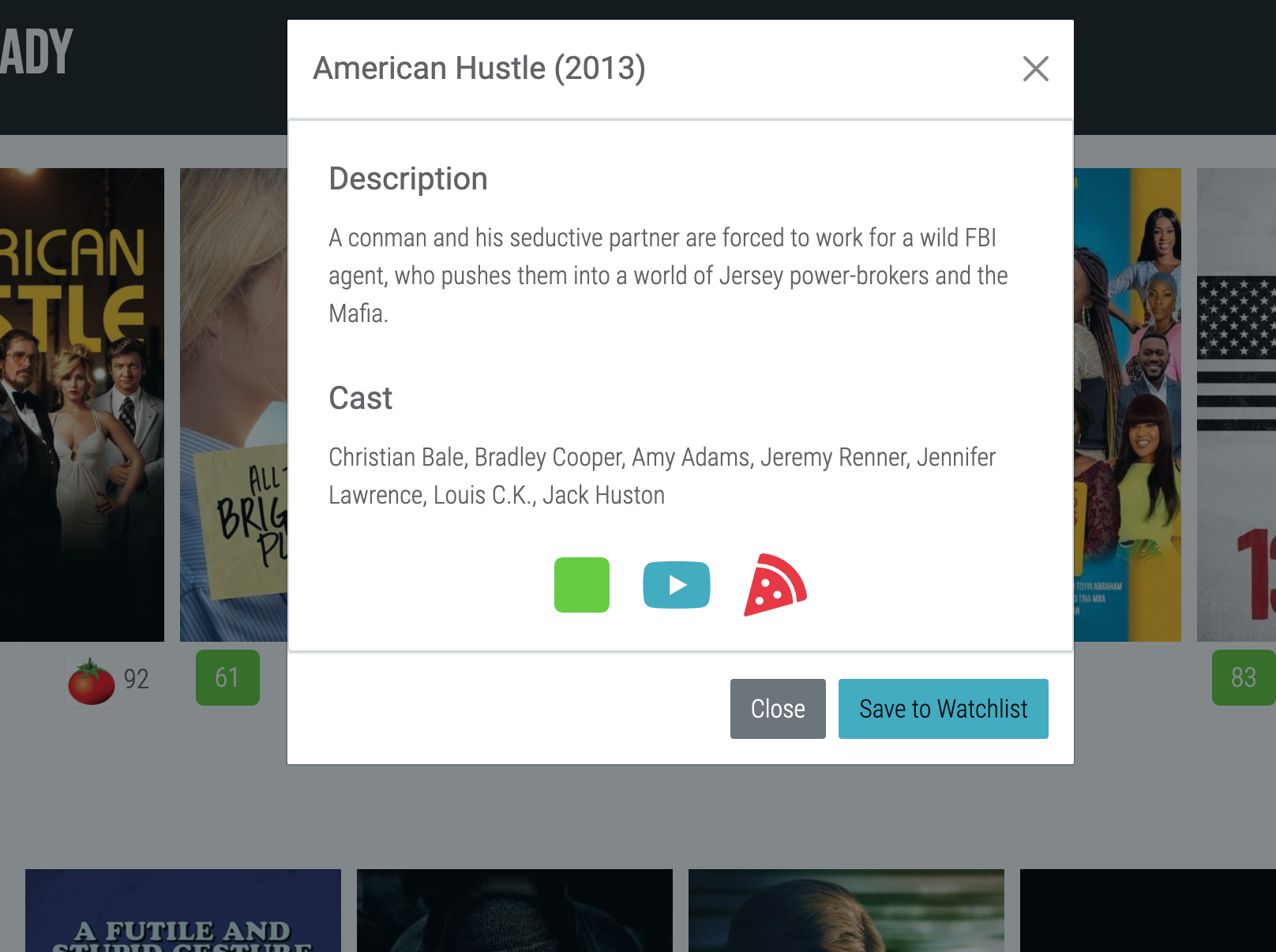
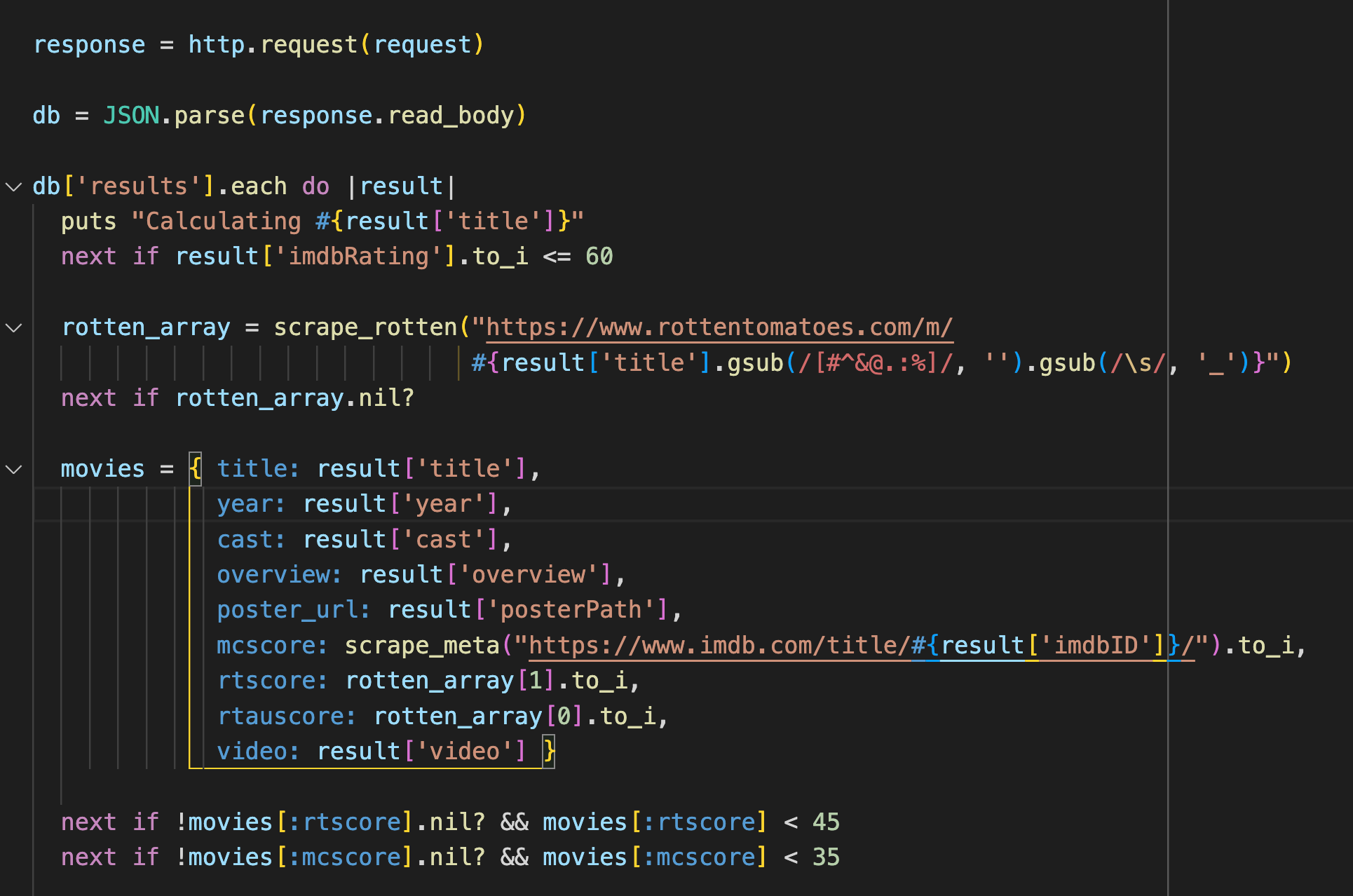
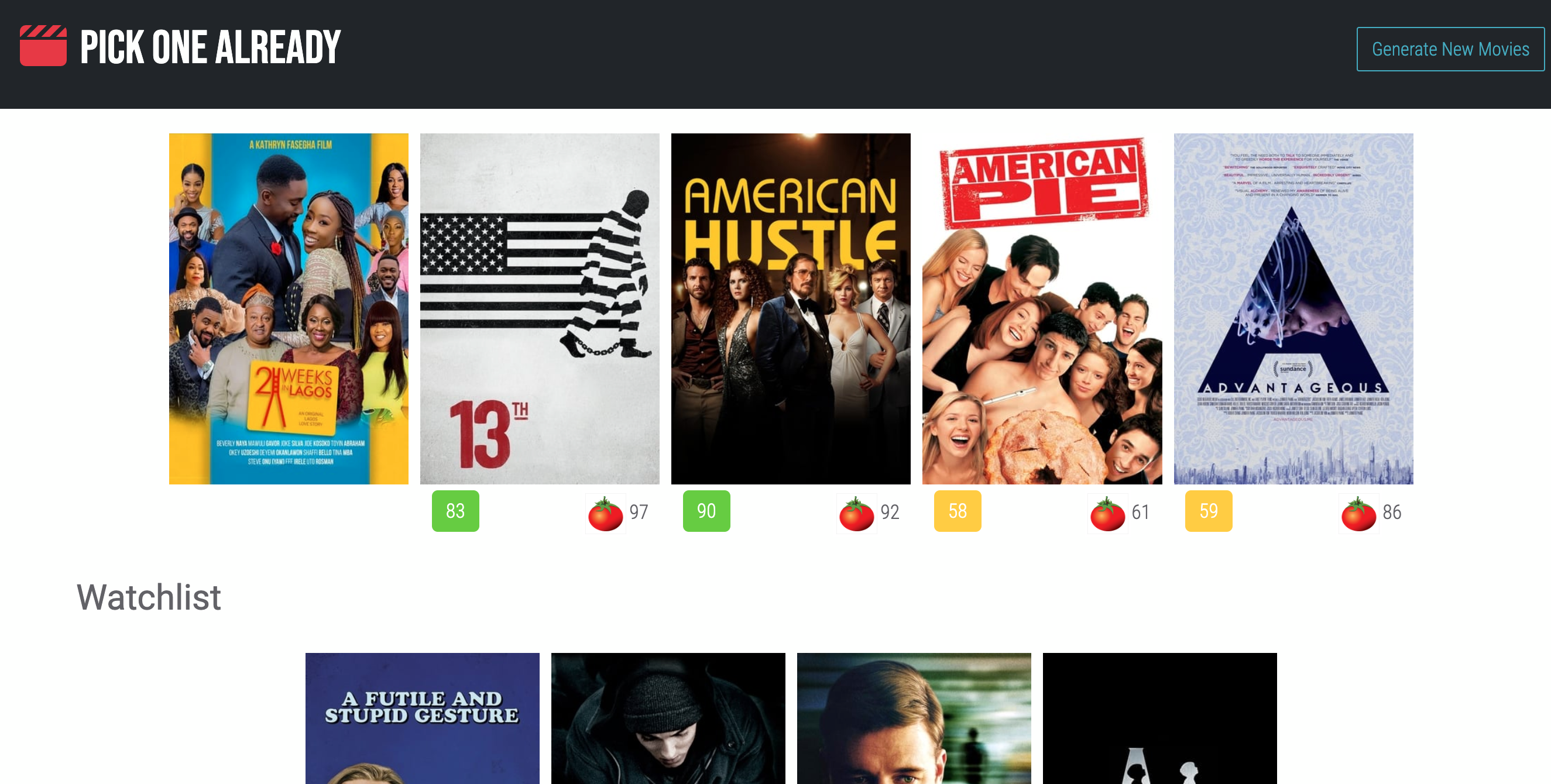





Scraping For Ratings with Nokogiri
For both rating websites, after the url is parsed and checked to see if it is a valid url (aka, it does not generate a 404 error), Nokogiri is used to read the parsed html. For IMDB’s website, it was simple to find the metacritic tag and strip to down to rating value. For Rotten Tomatoes, this was more complicated. Finding the right class was difficult due to the amount of scores on the page and the interference of javascript that made some values hidden from scraping. It was only when I downloaded the html from a test page that I was able to find the correct tag to find and its hidden attributes.
Improvements to Make:
- Streaming Country Search Bar — With access to a VPN, the country of the streaming service does not matter. With the help of another API that shows the list of countries a movie is available on Netflix, the user can search to see if a movie they really want to watch is streaming.
- Automated Seeding — If I want to grow the database of the app, I need to do it by hand every day to escape the limitations of the API.
- List by Genre — Streaming Availability has a genre field that can be utilized to generate movies of a specific genre.